看ChatGPT如何描述自己的前世今生?
11月11日,一则消息在社交网络上流传开来。据相关媒体报道,百度旗下的 AI大生产平台“百度大脑”与中国科学院软件研究所联合研发的 ChatGPT中文预训练模型已在百度世界大会上亮相。该模型基于多个主流 NLP数据集,经过多轮训练,能回答部分常见问题,如“请告诉我,世界上有哪些动物?”、“给我讲讲中国的四大名楼”等问题。

而 ChatGPT是一个通用文本生成模型,适用于新闻稿、博客文章、问答系统等多种任务。 AI技术发展至今,人工智能已广泛应用到各个行业领域。近年来,以预训练语言模型为代表的人工智能技术受到了广泛关注。
在使用这类技术的同时,人们也注意到很多问题。例如在训练数据方面存在的问题和数据量不足所带来的挑战;在训练过程中所使用的训练方法选择不当带来的效果差异;模型本身质量参差不齐带来的泛化能力不强等。因此人们也希望能够有一种能够全面提升上述问题水平和能力的通用型语言生成技术来解决这些问题。
它具备以下几个特点:
1.广泛连接不同类型数据
2.使用广泛且有效
3.良好泛化能力和训练效率


一、发展简史
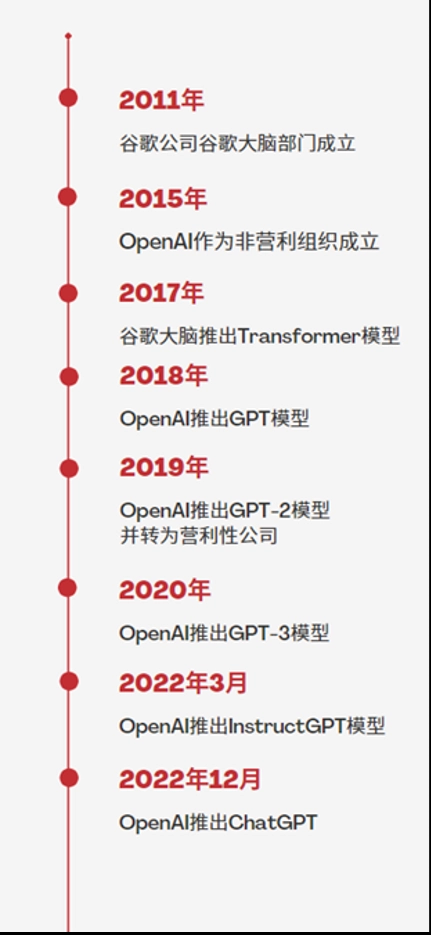
ChatGPT的发展和其他语言模型一样,经历了从简单到复杂、从以文本为中心到基于语料库的发展历程。 2020年3月, IBM推出了基于 BERT的预训练语言模型,并于同年8月获得了美国计算机协会 ACL 2020最佳论文奖。同年8月, IBM推出了第一个大规模预训练语言模型GPT-3。
此后 GPT经过不断升级迭代,逐步发展到如今的版本。 然而要想完全达到人类水平的语言生成能力并不容易。它需要一个庞大的语料库作为输入,并且经过大量多模态训练而得到一种高质量的语言模型(即预训练模型)。这种类型模型对系统性能有较高要求,只有在有足够数量、质量高和多元化数据集的前提下,才能获得较好的效果。
1、初始版本
ChatGPT初始版本的设计目的是用于进行计算机程序语言的预训练,并通过自然语言生成任务来收集大量的数据进行训练,以提高模型的性能。ChatGPT模型最初使用了 BERT等预训练模型作为参考。但是, BERT模型在基于文本的语言生成任务中存在着一些问题。
首先是对文本数据集的收集难度大。BERT需要从互联网上大量收集数据,并将其进行预处理后才能用于训练。而 ChatGPT使用的是网络爬虫和维基百科等语料库,这些语料库中包含大量未使用的文本和非结构化数据,因此对数据集搜集难度较大。
其次,模型也不能完全模拟真实语言环境。许多现实中存在的问题,如自动驾驶等自然语言生成任务都需要结合人类生成文本来进行分析研究;而在 ChatGPT中使用真实世界、开放域(如社交网络)中自然语言生成任务才能获得最好效果。
最后,对于生成质量和速度也是一个问题。GPT模型采用了许多人类和机器结合来生成文本,而这种模型不能快速完成文本输出任务从而导致产生大量无用信息。
2、发展历程
在 ChatGPT的发展历程中,有两个重要阶段:
第一阶段:简单、以文本为中心,把任务的输入分解为各个模块,每个模块独立训练并输出任务结果,其中一个模块可以包含多个任务。这种模型存在的问题是:任务之间缺乏关联性。它需要更大的语料库进行训练,但由于语料库不够丰富而无法提供足够多的任务关联数据。
第二阶段:以文本为中心的 GPT升级。这个阶段模型在对语料充分理解上取得了很大进步,同时引入了更多下游任务作为训练目标。这个模型将任务拆分开来训练并输出结果,一个模块负责一个较简单的任务。这种模型很好地解决了以文本为中心语言模型所存在的问题,但它没有在实际应用中取得很好效果。
3、最新版本
在OpenAI的官网上,ChatGPT被描述为优化对话的语言模型,是GPT-3.5架构的主力模型。
2022年11月底,人工智能对话聊天机器人ChatGPT推出,迅速在社交媒体上走红,短短5天,注册用户数就超过100万。
2023年1月末,ChatGPT的月活用户已突破1亿,成为史上增长最快的消费者应用。
2023年2月2日,美国人工智能(AI)公司OpenAI发布ChatGPT试点订阅计划——ChatGPT Plus。ChatGPT Plus将以每月20美元的价格提供,订阅者可获得比免费版本更稳定、更快的服务,及尝试新功能和优化的优先权。
在网友们晒出的截图中,ChatGPT不仅能流畅地与用户对话,甚至能写诗、撰文、编码。

二、工作原理
ChatGPT的主要原理是使用了一种基于生成对抗网络(GAN)的方法,它能够预测文本中下一个词的概率,并根据预测结果更新文本。
其模型结构为:
1.预训练模型:使用一种基于 LSTM和 CNN的预训练语言模型进行语言建模。其中, LSTM用于产生序列中下一个词的概率; CNN用于产生单词序列。根据下一个词预测出一个单词后, ChatGPT会根据预测结果更新文本。
2.生成模型:使用一种基于生成对抗网络(GAN)的方法,将输入文本作为输入来进行计算,然后输出另一个文本。
3.学习和训练:使用神经网络和批处理(Batch)对输入进行编码和解码。当输入和输出经过神经网络处理后,通过训练可以获得更好的性能。
4.微调模型:如果得到一个较好的预测结果,则会使用另一个更小的预测结果进行微调;否则会利用先前较大的预测结果进行微调。
5.可解释性:对于一些特定任务(如摘要、回答问题等),训练过程中可以看到模型使用了不同的方法(如生成式、生成式等)来学习相关知识或信息。
1、预训练
在 ChatGPT的模型中, LSTM和 CNN被用作用于产生语言表示的编码器,而 BERT作为生成器。
其中, LSTM用于序列(Seq2Seq)任务。在Seq2Seq任务中,一个句子将被转化为三个向量:句子中的词、句中的短语和句中词之间的语义关系。因此,我们可以使用 LSTM来捕获句子和短语之间的语义关系。 CNN被用来从输入文本中提取特征。对于输入文本来说,它们与真实世界中的人类语言有相似之处,即从词频、距离等信息中提取特征,如语言相似度、语义相似性等。
最后一层是由 BERT产生的训练数据组成。BERT是一种文本分类模型,可以从英文句子数据集中学习特征来进行分类。通过将每个单词与预先定义的标签相匹配来学习特征, BERT将学习到的单词标签作为输入到其模型中进行分类。 为了让模型训练过程更加顺利,我们需要使用许多不同类型的数据集来对模型进行训练和验证:如: ICDAR、TRI-RL等语言理解类数据集;如:英文文本分类、英文问答、Word2vec等文档生成类数据集。
2、生成模型
ChatGPT使用的生成模型是一种基于生成对抗网络(GAN)的方法,它由两个模块组成:一个是条件概率生成器(Curve Propagation Machine),另一个是条件判别器(Condition判别器)。
Curve Propagation Machine通过训练一个多层感知器来从原始输入序列中推断出概率分布。它学习如何对当前输入进行预测,并将其输出作为真实输出。当 Curve Propagation Machine预测出概率分布时,它就可以对下一句话进行预测。
Condition判别器通过学习判别式和条件概率分布的差异来生成假的概率分布,其目的是找到一些在条件概率分布上看起来更好的样本。这些样本的特征有两个:
(1)原始输入序列中有一个词在条件概率分布上表现得很好,并且它和这个词相关;
(2)生成器从原始输入序列中推断出一些假的特征,并且它和这个词相关。
另外,还有一些辅助信息能够帮助模型学习判别式和条件概率的差异,例如句中有两个单词对应着不同的条件概率分布。
3、学习和训练
在训练过程中,可以使用多种不同的神经网络模型(如 LSTM、 CNN和 CNN+ LSTM)。例如,使用 CNN作为 LSTM的输入。为了将数据编码到具有相同结构的、可共享的输入上,生成对抗网络(GAN)可以在每个输入上产生一个输出。
因此,如果输入是 CNN+ LSTM的组合,则生成对抗网络可以通过两种不同的方式学习:
第一,使用预测作为输入;
第二,使用与已知文本相关的输入来构建特征表示。 例如:根据下面表格中的信息,我们可以预测出以下词语:“气象报告”、“股票”以及它可能是什么?本文中与之相关的关键信息是天气(情景)和气象(数据)。
那么 LSTM模型就会将这些信息与 CNN进行结合: 其中 LSTM模型得到了预测。 当模型生成出一个文本后,会进行微调以使其更准确。

三、技术优势
在自然语言处理技术的发展中,计算机能完成对语言的理解并进行翻译和生成,但是这种理解和生成是以庞大的训练数据为支撑的,通常需要多个语言模型协同工作才能实现。因此,人们在对预训练语言模型进行进一步研究时也把目光转向了基于不同数据的大规模多任务学习模型。
在此基础上,为了提升预训练语言模型在实际应用中的效果,人们开始了对通用模型的探索。例如通过加入从大量文本数据中提取知识并与其他训练过的 NLP模型一起使用进行联合训练以提高其性能。 但预训练语言模型由于其强大的计算能力和庞大的数据规模被应用于很多任务中,例如问答系统、新闻生成、语音合成等。
但在这些领域也存在着一些问题亟待解决:
1.这些领域需要非常强且大量有效地可理解性输出才能满足使用要求;
2.这些领域无法充分利用已有训练集进行训练;
3.无法充分利用已有训练集进行迁移学习和其它预定义技术。
因此需要在各领域之间建立某种联系或者一些通用知识体系来促进各领域之间合作,进而达到全面提升这些领域水平和能力的目的。
1、强大的可理解性输出能力
目前,能满足可理解性输出的模型主要有两种:一种是将知识嵌入到模型中,从而赋予模型输入和输出语言信息的能力。例如基于知识图谱的结构化语言模型、基于 Encoder的序列生成问答系统等。另一种是将预训练的知识嵌入到一个通用的知识表示学习算法中,从而赋予模型更加强大的可理解性输出能力。
ChatGPT在可理解性输出方面具有很大优势,因为它将语言信息和各种领域知识(如常识)结合起来,从而产生了强大的可理解性输出能力。 ChatGPT在一开始就向人们展示了它是如何工作的:
首先,它对一个给定文本进行简单摘要;
然后,它使用一组简单词进行猜测,并将猜测结果与 Encoder中给定单词进行比较以获得上下文信息;
最后,它使用一系列其他领域知识来生成答案。这样, ChatGPT就可以根据 Encoder中给定句子或上下文来回答问题或生成答案。 在进一步在 ChatGPT中加入常识是其作为通用模型之一大有用处。
例如当用户问“今天是什么日子?”
ChatGPT会先回答“今天是7月23日”再回答“今天是星期一”;
而当用户问“你最喜欢吃什么?”
ChatGPT则会回答“我最喜欢吃火锅、春饼和薯条,也喜欢喝可乐、冰淇淋和啤酒。”
当用户提出问题后, ChatGPT会先对输入进行初步处理:然后它用少量文本描述一个事件或问题(例如用一个句子来表示这篇文章的标题),并根据一些基本常识(如天气情况、季节、日期和时区等)来推测这个事件或者问题。
最终, ChatGPT会利用这些知识对回答进行修正。ChatGPT会先告诉用户目前天气是晴天还是阴天、接着告诉用户有风还是没风等内容。
2、利用已有知识进行预定义
目前的预训练语言模型大多采用了多任务学习的方式,将多个 NLP模型联合训练,通过在多个 NLP任务中进行预训练来学习多个任务中的通用知识。例如 MuchCornerNetwork是一个以两个 GPT为基础的预训练语言模型,它通过利用 GPT进行大量的预训练来学习分类、问答、生成等任务所需知识,同时也可以把 MuchCornerNetwork的知识迁移到其它任务上,提高了 NLP模型在多个领域的能力。
BERT和R-Learing都是将多个预训练语言模型联合训练以获得更好的效果。 另一方面,通过利用已有知识进行预定义也可以提高其泛化能力。例如在R-Learing中,研究者提出了一个名为“反向传播”(back propagation)的优化算法来训练一个跨领域模型,通过将之前积累的知识应用到新任务上来达到提高模型泛化能力目的。因此,利用已有知识进行预定义可以使模型在特定领域或特定任务中取得更好效果。
3、自动领域适应能力
ChatGPT提供的知识能够自动根据任务对语言模型进行扩充。例如,在上述例子中, ChatGPT能够自动根据问句中的关键词扩充问句对应的模型知识,并且使用已有知识对结果进行验证。
另外, ChatGPT在自我训练过程中,并不需要进行额外的微调操作,从而为应用领域提供了一种更为灵活的模型结构。 在未来有了更多领域支持后, ChatGPT会具备更强的自适应能力。例如根据不同任务需求和语言环境构建不同知识体系,自动根据任务类型和环境进行知识调整等。未来在聊天机器人和问答系统等应用上将有更加强大的表现。
目前已有不少研究人员开始利用 ChatGPT来提升自然语言处理技术中各领域之间的联系。例如提出了一种全新的面向多任务学习模型架构 RGAN。此外通过对领域模型进行训练来增强智能问答系统等应用中语言模型与人类语言之间联系。
四、应用领域
ChatGPT在语言生成方面表现出色,在多个领域都有所应用,例如:
1.新闻稿:根据输入文本,自动生成新闻通稿;
2.问答系统:根据输入文本生成问答信息;
3.语音识别句子中的语音并自动翻译成文字;
1、语音识别
ChatGPT技术可以基于对话内容进行语音识别,比如对对话中的一句话进行识别,并自动翻译成文本输出。在一些语音对话系统中, ChatGPT可以替代人类进行语音识别。相比于传统的文本机器人, ChatGPT能够通过对特定任务的处理来产生具有个性特点的模型,并可在整个工作流程中执行端到端的训练。 与其他语言模型相比, ChatGPT能够处理多个语言模型所没有的数据(例如上下文信息)和多个任务(例如知识图谱)。
另外,在不了解用户意图或上下文信息之前, ChatGPT能将知识和规则添加到模型中,并将这些规则用于语言交互。 ChatGPT是目前唯一可以完全由训练数据来生成理解语言的模型。与其他语言模型相比,它能够为用户提供更自然地生成文本内容以及更自然地理解意图等能力。
此外,如果一个人没有学习过语言知识或者不熟悉标准输入语音中所使用的规则时,这将是一个重要优势。目前已有一些研究机构或公司在使用 ChatGPT来为用户提供服务或者体验。
2、文本生成
在生成文本方面, ChatGPT在语言生成能力方面表现出色,在自然语言理解基础上,以丰富的语义和上下文知识为支撑,实现了对多种不同类型文本的生成。
与一般的文本生成模型相比, ChatGPT具有以下优势:
(1)强大的语义理解能力:通过学习海量的高质量语料, ChatGPT能够有效识别并理解上下文信息和语言知识。
(2)自然语言表达能力:通过预先训练的语言模型,可以模仿人类对话中的口语、动作和表情等多种语言行为,从而实现对给定文本内容进行准确的生成。
(3)理解用户意图并生成回复:在自然对话系统中,用户输入文本后自然希望能够获得更加理想的回答,而 ChatGPT模型能够通过不断学习高质量语料及对各种不同类型文本信息进行学习、模仿,从而能够快速理解用户意图并作出回复。
(4)学习历史经验知识:不同于一般模型从给定的一系列训练样本中学习经验知识进而实现对任务目标和任务内容进行预测。ChatGPT在训练过程中通过预先获取大量历史数据来不断学习新数据并构建相关模型来更好地完成任务。因此可以通过历史数据和对不同任务内容的分析来更好地理解任务内容及其意图。
(5)自适应性: ChatGPT能够根据用户输入文本自动生成回答用户问题。如果 ChatGPT不能很好地回答用户问题,它就会自动调整语言模型并让其在给定文本中尽可能准确地找到答案。
(6)良好的对话管理能力:与其他基于自然语言处理技术实现聊天机器人不同, ChatGPT还可以通过定制聊天机器人与用户建立更深入、更具互动性的交流。通过在聊天机器人中嵌入 ChatGPT模型来提高对话管理能力。对话管理功能可以帮助机器人提供友好、灵活且易于理解并易于使用的体验。
3、问答系统
问答系统是人工智能在垂直领域应用的一种典型场景,是通过自然语言处理技术与知识库相结合的方式来帮助用户解决问题。目前, ChatGPT在问答领域已经有了较高水平的表现,其自然语言处理能力已经能够处理包括图片、文本等多形态的数据。
一问一答是问答系统的基本形式,指计算机通过自然语言理解用户问题之后生成相应回答。该能力可以帮助用户从海量数据中提取相关信息并形成答案,极大提升了人机交互效率以及服务质量。
例如:
在金融领域中,该技术可帮助金融机构设计并开发智能客服系统,通过对用户需求分析和解答获取相关信息以精准为用户提供服务;
在医疗领域中,该技术可以帮助医疗机构设计并开发智能客服系统,通过对用户需求分析和解答获取相关信息以精准为用户提供服务;
在教育领域中,该技术可帮助教育机构设计并开发智能客服系统,通过对用户需求分析和解答获取相关信息以精准为用户提供服务等。
目前 ChatGPT在问答领域已经有了非常优秀的表现:
(1) ChatGPT拥有强大的语言理解能力以及常识知识储备能力;
(2) ChatGPT拥有大量的专业知识与专业词汇;
(3) ChatGPT可以根据输入文本进行多形态、多知识储备信息抽取以及答案生成等;
(4) ChatGPT可以理解语言、并根据语言做出回答。例如:在金融领域中,可以基于输入文本进行多形态、多知识储备的信息抽取并生成相关回答。
综上所述: ChatGPT是一种非常优秀的语言模型。该模型支持大规模多形态信息提取和答案生成等功能,能够满足各个领域需求;其在问答领域具有出色的表现及效果,已被广泛应用于金融、教育、医疗等各个领域中。此外,该技术也被应用于新闻稿生成与写稿等方面。ChatGPT以其自然语言理解能力以及强大的语言生成能力在问答领域表现出色且具备很高水平。
4、视频分类与识别
ChatGPT在计算机视觉领域的应用中,也具有一定的潜力,其最大的优点就是可以快速生成视频并进行分类和识别。目前已经有不少团队在利用 ChatGPT来进行视频分类与识别工作中。例如:阿里巴巴集团旗下的达摩院、商汤科技,腾讯旗下的云从科技、华为,以及百度旗下的度秘科技等国内公司都已经将 ChatGPT应用在计算机视觉领域中了。
对于 ChatGPT而言,其能够对输入图片进行特征提取和语义分割,并将其转换成更有效的描述形式。同时, ChatGPT能够通过用户设置并自主选择生成训练数据。在训练过程中,用户可以选择任意图片作为样本,并设置好训练参数和微调参数之后即可进行 ChatGPT模型训练。相比于传统 AI模型而言, ChatGPT通过大量自然语言处理数据进行建模与推理、学习和自我更新等一系列过程后生成的模型更加智能且可靠。
目前国内已经有一些团队利用 ChatGPT来对视频进行分类与识别工作了,例如:360视觉、中国知网、腾讯等公司都推出了基于 ChatGPT的视频分类与识别应用工具。通过这些工具能够帮助用户在视频分类、识别等多个任务中更为高效地完成工作。
五、前景展望
从技术发展历程来看,语言生成领域经历了三个阶段。
第一阶段是从上世纪70年代至90年代,那时主要是基于统计模型的多任务学习技术的探索,如 GPT、 BERT等;
第二阶段是从2000年至2010年左右,主要以自监督学习为代表;
第三阶段是2012年以来,以 NLP领域为代表的大规模预训练模型技术。
ChatGPT可能会发展为一个非常强大的自然语言理解系统。 未来我们会看到更多的大规模预训练语言模型技术应用于更多任务中以解决人类所面临的问题。随着预训练语言模型技术进一步发展和完善,相信未来会有更多任务将使用这些技术来解决人类面临的问题。
*本文由AI自动生成,如有任何措辞及不正确的地方,如果喜欢,可以在社群里自有讨论。欢迎给我们提更多宝贵的意见。








